

One Dictionary to Rule Them All?
My favorite kind of mobile application is the dictionary. The home screen of my phone is filled with my favorites.

I have a specific dictionary app for each of the languages that I know or am learning, as well as a few "utility" applications (like Reverso Context, Linguee, and DeepL) that provide conjugation tables, contextual examples, and machine translation.
Naturally over the years, as I learned new languages and the number of dictionary applications on my home screen piled up, I began to wonder if it would be possible to create a single app that could provide basic dictionary functionality for multiple languages?
Of course, it makes sense for each language-specific app to have advanced features that are advantageous to that particular language (e.g. my Japanese dictionary app offers a view for exploring the subcomponents that make up more complex characters). But my most frequently desired actions are relatively simple. Most often, I simply want to type a word in one language (usually English, but not always) and then to quickly see a result list of possible translations of that word in the target language. My second most desired feature is the ability to "save" a particular word to some kind of vocabulary list for future reference and review.
After talking about this with other language-learners and polyglots, I realized that I wouldn't be the only one to benefit from this simple, multilingual word-to-word reference application. I also wanted an excuse to try building something with React Native, so I started mocking something up.
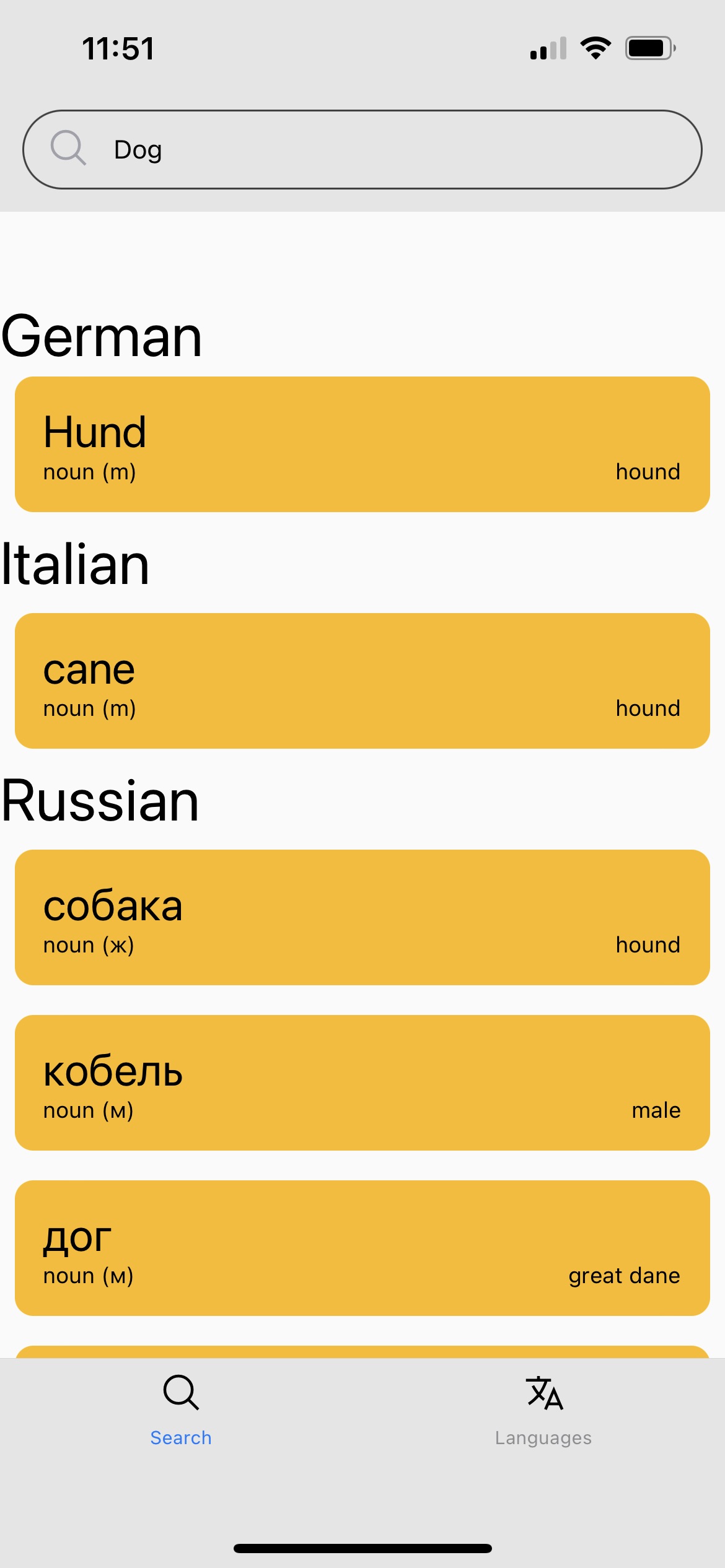
The basic idea is that users have a settings screen where they can select and save which languages they are interested in. Then, from the search view, users can search any word and the app will display the corresponding translations in all of the languages that the user has subscribed to, as well as a brief grammatical overview (noun, verb, grammatical gender) and indication of which "sense" of the word is being displayed.
A simple enough application and interface. (Ignore the ugly mockup colors.) The real design challenge? The dataset powering the application.
Searching for a multilingual dictionary dataset
I started looking for an existing multilingual dataset to use. Right away, I found a few services, mostly provided by traditional multilingual dictionary companies, that offered metered APIs for word lookup between languages. After poking around their offerings, I quickly realized that using one of these wouldn't be a good route for my application.
In the first place, every API was designed for looking up words in one (specified) language, and returning translations in a single other language. In other words, lookup was done by language pair. This means that many different API calls would be necessary for one lookup in my application. The application would have to ping an /check_entry_exists query for each of the possible input languages in order to see if an entry exists for that language. And then, if it does, the application would need to ping multiple /get_translations_in_target_lang queries for each language that the user subscribes to. For a user that knows or is interested in learning six different languages, that means at least twelve separate API calls per word lookup. Which brings us to the second issue with these APIs.
Each of the APIs I found was billed by usage. For development and testing purposes, this was fine, as most provided a "free usage tier" for up to between 100–1000 daily API calls. (I actually used Yandex's Dictionary API for the mock up.) But assuming around twelve API calls per lookup, even if the application only had 1000 users making an average of 20 lookups per day, the bill would add up very quickly.
And besides, my favorite feature of all of my dictionary applications is that they offer the ability to download at least a basic version of their dataset, to allow for lightening-fast offline lookups. For me personally, when I'm looking for a new dictionary application, the ability to have offline access is non-negotiable, and I doubted that I would be able to convince any of these services to let me license and download their entire dataset.
So I started looking into other options. Was there an open-source database that I could use? Hmm, not really. Again, I found a few small datasets for individual language pairs, but nothing approaching the level of multi-language support that I was hoping to find. Eventually, I had the thought that strikes fear into every project manager's heart: "What if I built it myself?"
The internet's most popular community-edited dictionary,Wiktionary, periodically releases massive "dumps" of all of their data. This seemed like a promising pathway, made even more promising when I discovered a project called Kaikki.org, which calls itself a "digital archive and a data mining group" that parses and disambiguates some of Wikitionary's multilingual data and offers the results as (massive) downloadable json files. (Interestingly enough, this project is led by the same person who wrote the initial ssh protocol!) Given this extremely large multilingual dataset, my thought was that I should be able to shape it into something I could use for my own purposes. But how would that look?
Thinking about Data Structure
In order to decide how to process and shape the Wikitionary dumps into a useful data structure, I thought that I would start by working out what I wanted the API responses received by my dictionary application to eventually look like.
I figured the request from the client would look something like the following, containing the text of the search as well as a list of the subscribed languages.
{ text: "trip", langs: ["en", "de", "it"]}The server backend would then figure out which language(s) the inputted search term was in, find the relevant translations, and send back some kind of simplified response:
{ text: "trip", pos: "noun", // part of speech lang: "en", sense: "an excursion, journey", translations: [ { lang: "de", text: "Reise" }, { lang: "it", text: "viaggio" } ]},{ _id: "en-XYZXYZ" text: "trip", pos: "verb", lang: "en", sense: "to fall, stumble", translations: [ { lang: "de", text: "stolpern" }, { lang: "it", text: "fare un passo falso" } ]}Note that in the above response to the English search term trip, there are two distinct objects: the noun trip (excursion, passage) and the verb trip (to fall, stumble). Each of these two 'senses' of the search term that the server found have the appropriate German and Italian translations associated with them. In order to deal with this kind of disambiguation of terms, not only does the data structure need to provide for entries in a language, but also possible separate senses for each entry. Even words that only have one part of speech can have multiple senses. Consider the English verb to run, which can mean to physically move quickly as well as to initiate (computer program, maneuver).
In order to see how others have dealt with this, I opened a physical dictionary and looked at how the data was structured. I found that each entry has a 'headword', usually printed in bold, that includes the base form of a word (i.e. 'run' and not 'runs' or 'ran') as well as its part of speech (noun, verb, adjective, etc.). Below that headword are multiple numbered 'senses' of the word, each including a definition and a usage example. In a bilingual translation dictionary, each sense of the word also has the appropriate word-sense translation listed in the other language.
With this in mind, it was clear to me that my data structure would need to maintain some difference between an 'entry' for a word and the various 'senses' that entry could contain.
So after looking at the data available from the Wiktionary dumps, I devised two data structures, one for a word Entry and one for each Sense of that word:
// ENTRY{ id: lang-EN-uuid, lang: string, headword: { text: string pos: string }, senses: [SENSE], forms: [{ /*...*/}] sounds: [{ /*...*/ }], etymology_text: string,}// SENSE{ id: lang-SE-uuid, glosses: [{lang: string, text: string}], // text in various languages defining the word-sense examples: [{ /*...*/ }], tags: [string], // e.g. obsolete, archaic, slang, countable, etc. sem_cats: [string], // semantic categories: agriculture, fishing, business synonyms: [{id: ENTRY.id, text: string}], antonyms: [{id: ENTRY.id, text: string}], hypernyms: [{id: ENTRY.id, text: string}], meronyms: [{id: ENTRY.id, text: string}], derived: [{id: ENTRY.id, text: string}]}In addition to storing the relevant information from the Wikitionary dumps, each Entry or Sense record has its own unique id, so it can be individually referenced. This would allow for the application to implement a 'detail view' for each entry, where the application would make a separate API call to pull up the more specific information (such as examples, synonyms, and verb conjugations) that don't need to be displayed in the search view.
But there's one major piece missing from the data structures above: the translation information! In following the exact model from the physical dictionary, the most logical thing to do would be to store a reference (via the unique id) to the translated entry in the Sense structure:
sem_cats: [string], // semantic categories: agriculture, fishing, business+ translations: [{+ lang: string,+ id: ENTRY.id+ }] synonyms: [{id: ENTRY.id, text: string}],This would work in that it would allow us to generate the desired output above, but if we think about how the dataset might grow and change over time, we run into a few issues.
Imagine that at the beginning of our dataset, we only have two languages: English and German. In the Sense record for the English word-sense for to run (physically move quickly), we could store the reference to the corresponding German word-senses. And we could do the reciprocal in the German word-sense and store the reference to the English. But what happens when we add Spanish language data to the dataset? When we add the Spanish equivalent word-sense for to run (physically move quickly), what do we have to do to our dataset? Not only do we have to add the references for the English and German word-senses to the newly added Spanish record, but we also need to add the Spanish reference to both the English and German records.
This sounds simple enough for a small number of languages with complete translation parity across the whole dataset, but what does this operation look like for a dataset with 20 different languages with only partial translation coverage among them? How are we going to keep track of these word-sense-translation bindings across this kind of dataset?
A lemma-based approach
To answer this question, I turned to my psycholinguistic education and recalled the idea of the lemma. In the psycholinguistic context, a lemma is the "abstract conceptual form of a word" that is thought to be selected by the brain as the first stage in the multi-staged process of 'lexical access'. Simply put: some linguists think that when we are trying to think of a word, we actually think of the 'underlying concept' of the word first, and then that later, specific features (spelling, pronunciation, grammatical gender, etc.) are retrieved in a different cognitive process.
Whether or not this is true is entirely beside the point for our purposes here (although it is very interesting). The point that I want to make here is that we can think of the word-senses of each individual language as being 'surface representations' of an 'underlying abstract concept'. If we store these abstract concepts as their own type of data, and then store references to their corresponding representations across the different languages in the dataset, we suddenly have a centralized way of managing the binding problem mentioned above.
In my dataset design, I represent these abstract concepts as a third data type called Globalsense, which has the following structure:
// Globalsense{ id: GS-uuid, glosses: [{lang: string, text: string}], entires: [{lang: string, text: string, entry: ENTRY, sense: SENSE}]}Each Globalsense record has a unique id, a list of glosses in different languages, and list of entries across the different languages in the dataset that contain 'surface' representations of this 'underlying' concept. Note that for every unique "sense" of a word in the dataset, a new Globalsense will be created. If a word in a newly added language is deemed to have roughly the same meaning, it will be added as an entry to this Globalsense. All members of a particular Globalsense's entries list should be valid translations of each other. While the Globalsense holds a list of possible glosses in different languages, in order to make its meaning understood to the user, the Globalsense itself is language-agnostic. It will only ever be referenced or looked up by its ID.
To make this idea concrete, here is an example of what this data might look like for the example presented above with to run (physically move quickly):
// Globalsense example - to run (physically move quickly){ id: "GS-000123", glosses: [ {lang: "en", text: "to run (physically move quickly)"}, {lang: "de", text: "laufen (sich körperlich schnell bewegen)"}, {lang: "es", text: "correr (moverse físicamente con rapidez)"} ], entries: [ {lang: "en", text: "to run", entryID: "en-EN-000020", senseID: "en-SE-000045"}, {lang: "de", text: "laufen", entryID: "de-EN-000033", senseID: "de-SE-000072"}, {lang: "es", text: "correr", entryID: "es-EN-000062", senseID: "es-SE-000091"} ]}(Thinking ahead about database implementation for a second, you'll notice a small amount of data denormalization in the inclusion of the text property in each object in the entries array. Technically, this text information is accessible through the entry object referenced by the entryID. But because of the frequency that I anticipate these records being queried, I've decided to duplicate the most basic piece of information (the word itself) and include it in globalSense record. More on these considerations later.)
In order to associate a word-sense record with its Globalsense, for use in querying the database to get associated translations, we also need to store a reference in the Sense record. This can be done when the record is first instantiated in the dataset:
// SENSE{ id: lang-SE-uuid,+ gs_id: GS-uuid, glosses: [{lang: string, text: string}], ...}Now, if we were to add a new language to the dataset (say, Italian), all we need to do is update the Globalsense record with the reference to the new Italian word-sense record. Now, When any other entry in the other languages is accessed and the dataset is queried for the associated Globalsense record, the new Italian language translations will automatically be present. No need to update any of the English, German, or Spanish records.
Considering database options
With these three data structures of Entry, Sense, and Globalsense, it's possible to build the data layer powering this application. The question now becomes how to actually implement it. Should we use a relational database (like MySQL or Postgres) or a NoSQL database (like MongoDB or Cassandra)?
The simple data structures outlined above could easily be implemented in any of these systems without too much trouble, so the question becomes one of performance, evolution, and familiarity considerations.
Performance
When considering database performance, the first question is: what kind of performance are we talking about? Query performance, write performance?
For our application, it's clear that query/read performance is the most important factor. Every time a user searches for a word or pulls up a detail page, data needs to be queried and fetched from the database. This could (and hopefully does) happen hundreds or thousands of times per minute, with requests initiated by multiple users at the same time. We don't want the user waiting around for this information to load, so read performance is crucial. Writes to the dictionary data, on the other hand, will only happen occasionally. When writes do happen, they will probably happen in large batch jobs (adding new data for an entire language). For this reason, write performance is secondary. (For this reason as well, I have decided to ignore the discussion of data consistency.)
Keeping in mind that we have a read-skewed workflow, there are still tradeoffs between relational and NoSQL systems. If these read operations involve lots of complex queries and joins, the schema-based approach and join-optimization of relational database systems would provide an advantage. On the other hand, data denormalization and duplication is another pathway towards increased read performance, and NoSQL database systems excel at storing this kind of denormalized data.
Without doing empirical tests, it's hard to say which of these approaches ultimately yield the fastest results, but as we'll see below, there are other compelling reasons to choose one model over the other.
Database Evolution
The other large consideration in this discussion is the future of the dataset. Right now, while I'm primarily working with language data from one source (the Wiktionary dumps), it's been easy enough to think of the shape that the database should have. But what will happen in the future when we add more data from different sources? When we add different languages that require completely different types of information?
For relational database systems, a database schema is required. Future changes to this schema are possible, of course, but can be difficult and confusing to manage and integrate with the old information. As new information is added and the schema is modified to accommodate it, things can get ugly. I've seen it before. (Don't believe me? Go have a look at OmegaWiki's database schema and how it has grown and changed over the years and then tell me what you think 🤮.)
NoSQL databases, on that other hand, are schema-less by design. Document-model databases (like MongoDB) are meant to be thought of as collections of independent documents, each of which can have its entirely own unique data structure. For our use case, this schema-less design is appealing, as it allows future Entry and Sense records to contain additional, language-specific information.
Familiarity with MongoDB
Ah yes, and one other important consideration to include here: I'm a independent developer working on a sideproject in my freetime and I'm already much more familiar with MongoDB than any other database! Don't get me wrong, I'm all for learning new tools, and the best way to do that is to implement them in new projects, but given the considerations above, as well as my familiarity with MongoDB and its quirks and tools, this decision was not a difficult one.
Implementing with a NoSQL database
So now to actually implement the darned thing. As mentioned above, our primary performance consideration is read/query speed. In implementing a document-based database like MongoDB for an API-driven application ours, we have to consider two main topics:
- Clever storage of frequently accessed data
- Limiting database queries over the network
Data Storage
In MongoDB, data is stored in documents. Each document is essentially a JSON object, with field-value mappings. Documents are stored together in a collection. Collections are essentially the same thing as tables in relational databases.
One advantage of this system is that data which frequently needs to be accessed alongside other data can be stored along with it, thereby reducing the need for joins and materialized views. For our data model, with its Entry, Sense, and GlobalSense components, the natural starting point is to consider each of these objects as their own document, grouped into their own collections. This would look something like this:
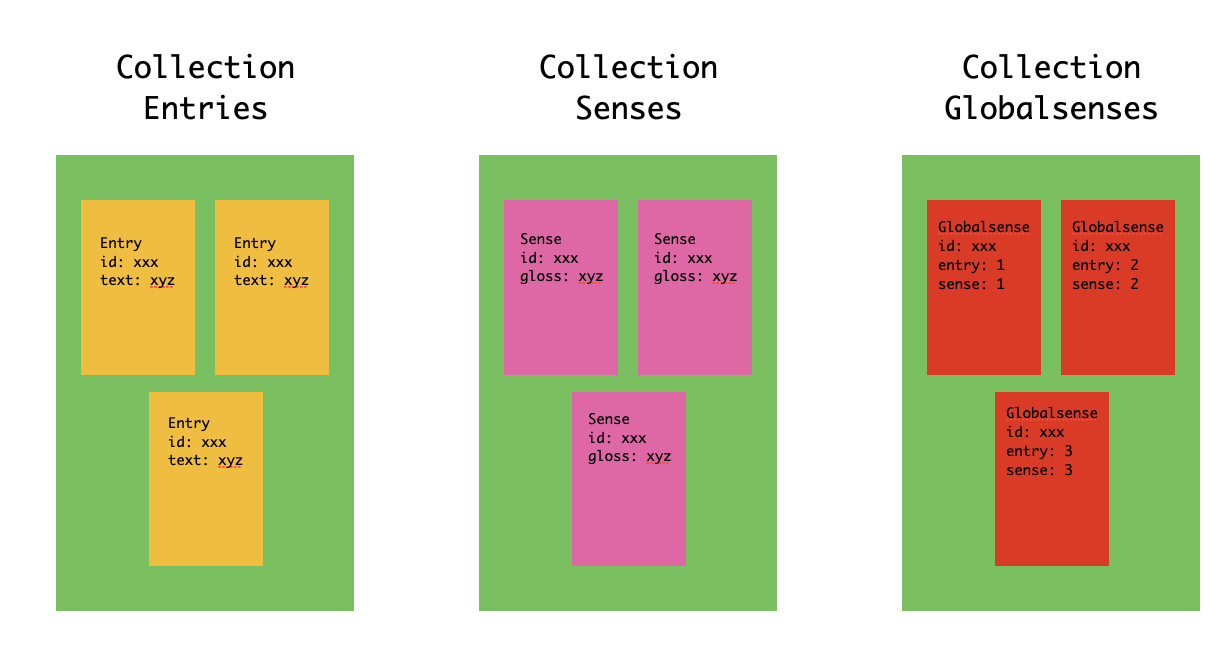
The advantage here is that each kind of data can be easily accessed by querying its containing collection.
mongo.db.entries.find_one({"headword.text": "dog"})// returns the following Entry document{ "_id": "en-EN-00000661", "headword": { "text": "dog", "pos": "noun" }, "lang": "en", "senses": [{ id: "en-SE-00000532" ... }]}mongo.db.senses.find_one({"_id": "en-SE-00000532"})// returns the following Sense document{ "_id": "en-EN-00000532", "gs_id": "GS-00000700", "glosses": [ { "lang": "en", "text": "Common four-legged animal..." }, ]}mongo.db.globalsenses.find_one({"_id": ""})// returns the following Globalsense document{ "_id": "GS-00000700", "glosses": [...] "entries": [ { "lang": "en", "text": "dog", "e": "en-EN-00000661", "s": "en-EN-00000778" }, ... ]}But it's important when optimizing read performance to think about the context in which different forms of data will be queried together. If we walk through our likely queries (word search and detail view), we find that we almost always want to return Entry and Sense records together. Any time we are showing the user an entry for a word, we are showing at least one, and usually all of its possible senses. If we organized the database such that Sense was its own collection with a foreign key reference stored in the Entry record, that would mean that almost every time we query a word, we are making multiple subsequent calls to another collection in order to retrieve the associated senses.
This starts to touch on point #2 as well. One advantage of the document-based structure of a NoSQL database like MongoDB is that we can embed documents inside of others. If every time we access the sense records, we also want to access the entry record for its parent word, then it probably makes sense to just store the sense records as embedded documents inside of the entry document. Accordingly, an entry document will look as follows:
{ "_id": "en-EN-00000661", "headword": { "text": "dog", "pos": "noun" }, "lang": "en", "senses": [ { "_id": "en-EN-00000532", "gs_id": "GS-00000700", "glosses": [ { "lang": "en", "text": "Common four-legged animal..." }, ] }, {...}, ]}By changing this storage approach, we've made it slightly more difficult to access individual senses on their own, but have reduced the need for additional database lookups for our most common queries. A happy tradeoff!
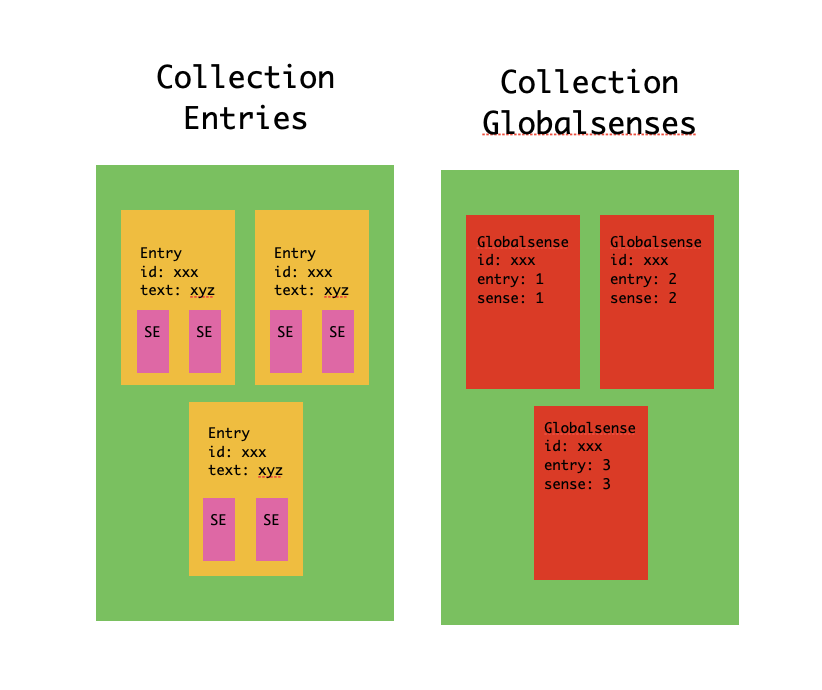
What about GlobalSense records? To avoid the "word-sense-translation bindings" problem that we mentioned earlier, it seems reasonable to leave the GlobalSense records in their own collection and to access them via a stored key (in this case, their unique id). This way, when a new word is added to the dataset and the GlobalSense record is updated with a reference to the new word, every other word entry that already references this GlobalSense automatically has an access path to the new entry.
While we were able to avoid having to do cross-collection queries to look up the associated Sense records for each Entry, we are going to have to do some of these queries to get the other Entry records in other languages when a user performs a search. Theoretically, we could store the full documents of every relevant translation inside of each word's Entry document, and thereby avoid another database call, but this would create a level of write-complexity and data duplication that seems undesirable. They are called tradeoffs for a reason.
So, seeing as we are going to need to make some of these cross-collection access queries, traditionally called joins in relational databases, we have a few options. These can either be performed in the application logic, or using MongoDB's aggregation pipeline. If we were to perform these lookups in the application logic, we would first need to send a network request to the database to get the desired Entry record, wait for it to be returned, and then imperatively parse through it to find which ids to ask for in a subsequent network request. In general, we want to limit the number of network requests as much as possible, so this is less appealing than the alternative.
Mongo's aggregation pipelines allow you to send one network request to the database with a series of declarative data operations called stages. The database will process this pipeline query and return the 'aggregate' result all at once, eliminating the need to multiple requests made by imperatively interpreted application logic. In this way, Mongo's aggregation pipeline can be thought of as similar to a standard SQL query for a database like MySQL or Postgres.
In particular, we are interested in the $lookup stage. Similar to a join query in relational databases, $lookup performs an outer left join across two documents, based on a given join condition. In our case, we are looking to join the entries field of the GlobalSense record to a particular Entry, in order to give the possible translations of a word. To do this, we'll use the gs_id field of each sense of a word to join the relevant GlobalSense record. (We'll also use a secondary pipeline to filter out the languages that we aren't currently interested in.)
The resulting operation looks as follows:
$lookup: {
from: "globalsenses",
localField: "senses.gs_id",
foreignField: "_id",
as: "translations",
let: {
langs: ["es", "it", "de"],
},
pipeline: [
{
$set: {
translations: {
$filter: {
input: "$entries",
as: "obj",
cond: {
$in: ["$$obj.lang", "$$langs"],
},
},
},
},
},
],
},Running this query on our database returns the following result:
{ "_id": "en-EN-00000661", "headword": { "text": "dog", "pos": "noun" }, "lang": "en", "senses": [ { "_id": "en-EN-00000532", "gs_id": "GS-00000700", "glosses": [ { "lang": "en", "text": "Common four-legged animal..." }, ] } ], "translations": [ { "lang": "de", "text": "Hund", "e": "de-EN-00000690", "s": "de-EN-00000759" } ]}Which looks remarkably similar to what we set out to achieve! In the returned object we have all of the information we need to present an overview of the possible translations for a given query, as well as the ability to link to individual detail views for a given word-sense in any language. Success!
Conclusion
It's my hope that this lemma-based GlobalSense approach and the according database considerations will provide an efficient dictionary API for the multilingual translation dictionary that I want to build.
While the data model is certainly more complex than traditional bilingual translation dictionaries, I'm hoping that careful database optimization and storage will allow the feature of being able to query translations in multiple languages at once to outweigh the increased query complexity.
Of course, the data considerations are actually a mere drop in the bucket compared to the real facet that this application will live or die by: the data quality. I'm currently working on an ETL/scraping pipeline to gather data from Wikitionary and other sources, but that's another blog post.